
Key Takeaways
- Model access is no longer a competitive advantage. The organizations pulling ahead are the ones grounding AI in knowledge their competitors cannot replicate.
- Most AI automation initiatives fail because they automate the idealized version of a process rather than how work actually happens. Closing that gap is the foundation everything else builds on.
- AI systems built on proprietary knowledge compound in value over time, creating a structural advantage that widens with every cycle rather than eroding as competitors adopt the same tools.
The Real AI Gap Is What the Model Knows
AI implementation has moved fast enough that most enterprise teams now access the same frontier models. GPT-4, Claude, Gemini. The capability gap between organizations has largely closed. What hasn’t closed is the gap between organizations using those models effectively and those that aren’t. We’ve run engagements across industries, and that gap almost always comes down to one thing: the data underneath the model.
Access to a frontier model is the starting point. What determines whether AI creates durable value is whether it’s grounded in what your organization specifically knows and how your organization actually operates.
The Model Access Problem
When a new model version ships, every organization gets the same capability update simultaneously. Any edge from early adoption disappears within weeks as competitors reach parity. Model access has become the baseline. Every organization on the same platform gets the same update at the same time.
Why Generic Models Fall Short
Generic models train on publicly available data. They’re highly capable at language and reasoning, and completely uninformed about your company. Deploying one without proprietary grounding is roughly equivalent to hiring a highly credentialed person with no onboarding and no access to internal context, then expecting differentiated work.
One client we worked with faced a churn prediction problem. They had access to the same AI tools as every other SaaS company in their space. Generic models could identify churn after it was already happening. What they couldn’t do was pick up on early warning signals. Nuanced support ticket trends. Subtle shifts in engagement behavior. Patterns the company’s most experienced Customer Success reps had developed an instinct for over years. The failure had nothing to do with model quality. The model simply lacked the context that team had built over years. That gap is the core of what we see organizations running into.

The Documented Process Problem
Here is the issue most AI initiatives run into before they ever get to a model: businesses have SOPs and workflows that describe how they think they operate. The real institutional knowledge lives somewhere else entirely. It lives in support tickets, system logs, Slack threads, and the heads of people who have been doing the work long enough to know where the official process breaks down.
That gap between documented processes and actual processes is precisely why most AI automation initiatives fail. They automate the idealized version of a process, not the real one. The output looks reasonable on paper and underperforms in practice because it was never built on an accurate picture of how work actually gets done.
This is the core problem Dactic was designed to solve. Rather than accepting documentation at face value, Dactic reverse-engineers reality first, then builds automation on top of what is actually true.
What Existing Approaches Miss
Most organizations attempting automation eventually encounter one of three dead ends.
DIY platforms like Make, Zapier, or AgentForce give you capable tools and assume you already understand your own processes well enough to configure them correctly. Most companies don’t, and that assumption is where the initiative stalls.
Traditional consulting documents the current state, hands over a report, and moves on. There’s no living feedback loop. The process map is accurate on the day it was written and increasingly outdated after that.
Generic AI agents are platform-level and process-agnostic. They have no knowledge of your specific workflows, your edge cases, or the institutional reasoning your team applies when the standard process doesn’t fit. Every decision they make is disconnected from your actual knowledge base.
Dactic sits in the space none of these occupy. It functions as a managed AI transformation layer that bridges the discovery work of consulting, the automation capabilities of modern platforms, and the ongoing feedback loop that keeps the system current as the organization evolves. The agents Dactic deploys are traceable to a specific knowledge library built from your actual operations, which matters considerably for audit trails and organizational trust.

The Institutional Knowledge Problem
Every organization carries the same underlying risk: critical expertise lives in people’s heads, with no system capturing it. The troubleshooting logic a senior engineer built over fifteen years. The pattern recognition a top sales rep acts on without fully explaining it. The deal evaluation instincts built over a career. When those people leave, that knowledge goes with them.
The Scale of What Gets Lost
In U.S. manufacturing alone, undocumented expertise loss contributes to an estimated $92 billion in annual productivity losses. Around 23% of machine downtime traces back to the absence of institutional knowledge needed to handle non-standard situations, rather than any equipment failure. These figures come from workforce and manufacturing research, but the pattern shows up across every industry and function.
A private equity firm we worked with built its edge on the deal evaluation instincts of a small number of senior partners. Their ability to identify high-value opportunities existed nowhere in documentation. It was accumulated judgment built over careers. They had access to the same deal flow databases and financial models as every other firm. What they hadn’t systematized was the reasoning layer sitting on top of those tools. That was where the actual alpha lived.

Why Traditional Approaches Don’t Work
Traditional knowledge management rarely solves this. It relies on voluntary documentation that’s slow, expensive, and consistently deprioritized by the people whose knowledge matters most. A single domain of expertise can take three to five weeks to document manually. At any real scale, that’s not a viable path.
How Dactic Approaches the Problem
The organizations that get this right share a common pattern: they treat knowledge capture as a prerequisite for AI deployment, completing it before agents are built or models are fine-tuned. Someone does the work of surfacing how the organization actually operates, separate from how its documentation describes it.
Dactic’s answer to this is structured discovery before any automation begins. We don’t start by asking what you want to automate. We start by figuring out what is actually happening.
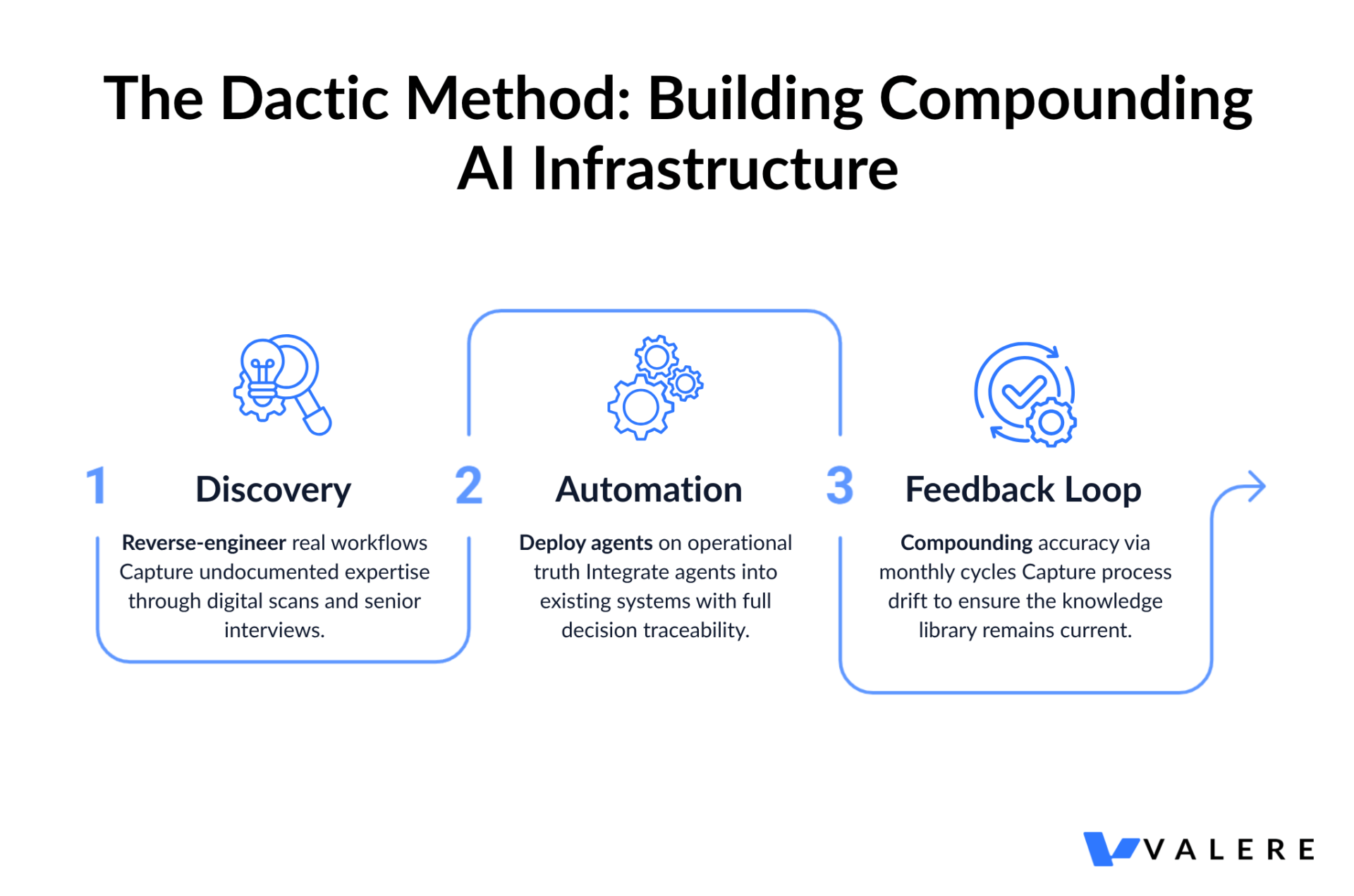
Discovery: Building an Accurate Picture
The first phase combines a Digital Footprint scan with structured interviews. The scan pulls from existing operational data — tickets, logs, message threads, service records — and reverse-engineers real workflows from the evidence of how work actually gets done. This surfaces the workarounds, the informal processes, and the edge case handling that never made it into any SOP.
The interviews capture what the scan cannot: the judgment calls, the contextual reasoning, and the institutional knowledge that exists in people’s heads and nowhere else.
We saw this clearly with a national construction delivery network dealing with subcontractor compliance. Alignment protocols existed on paper. In practice, field teams had developed their own workflows, workarounds that were frequently more effective than the official process but completely invisible to leadership. Surfacing that actual operating reality became the foundation for automation that worked with the business as it genuinely functioned.
The output of Discovery is an AI Playbook: agents mapped to specific processes, SOPs generated from actual workflows, and an ROI estimate before the automation layer goes live.
Automation: Agents Built on What’s Actually True
The second phase deploys agents directly inside existing systems. Every decision traces back to the knowledge library built in Discovery. There are no black boxes. You can see why an agent did what it did, which matters when teams need to trust the output and when compliance requires an audit trail.
The automation layer runs on existing infrastructure. Most deployments require no migration and no replacement of current systems. The goal is to enhance how operations function, built on an accurate foundation rather than an idealized one.
A construction technology company scaling email outreach to over 250,000 contacts tried generic AI copywriting first. The output was fluent and forgettable, content that could have come from any company in the space. After our knowledge capture process extracted specific buyer pain points, proven messaging patterns, and ICP nuances from their sales team, the output became their expertise running at scale in a form competitors couldn’t replicate by purchasing the same AI subscription.
The Feedback Loop: Staying Current as the Organization Evolves
The third phase is what separates a one-time deployment from a compounding system. Every month, the discovery process runs again. It surfaces process drift, knowledge gaps, and anything that has changed since the last cycle. Updates go to managers for approval before anything changes, so humans stay in control of how the agents evolve.
This monthly feedback loop is the strategic foundation of the partnership. Each cycle makes the knowledge library more accurate. More accurate knowledge makes the agents more reliable. More reliable agents become more deeply embedded in core workflows. The compounding relationship that builds from this is considerably harder to replicate than any software feature.
Who This Is Built For
The buyer we work with most often is an operations leader or COO at a mid-market service business. They’ve already tried automation. The tools weren’t the problem. The foundation was. They configured a workflow against their documented process and discovered, after the fact, that the documented process and the actual process were two different things.
Dactic sells the foundation. The Discovery phase surfaces the real operating picture. The Automation phase builds on top of it. The feedback loop keeps it accurate. The result is an AI layer that reflects how the business actually works, not how it’s supposed to work.

Outcomes Worth Noting
Organizations that systematically capture institutional knowledge and integrate it into their AI systems tend to see information retrieval improve 31 to 35 percent within weeks of implementation. Employee productivity increases 25 to 40 percent in affected functions. Most initiatives recoup investment within 6 to 14 months.
What This Looks Like in Practice
A federal contracting firm we worked with used this approach to score government contracting opportunities with substantially more precision than their previous process allowed. Standard models carry no knowledge of agency-specific relationship history, Navy contracting nuances, or the undocumented win and loss patterns that determine which opportunities are worth pursuing. We captured institutional intelligence from sales executives, engineers, and operations teams. The resulting system surfaced high-value targets 30 to 90 days earlier than their prior process. The advantage came entirely from the data layer, and data advantages don’t evaporate when a new model version ships.

A regional university running generic alumni outreach used a similar process to capture historical sentiment, qualitative feedback, and relationship nuances across its community. Intelligence specific to that community made those communications land differently than the standard institutional outreach recipients were already ignoring.
The Compounding Effect
Every interaction within a proprietary AI system generates new data that refines its accuracy. The more embedded it becomes in core workflows, the harder it becomes for competitors to catch up. The technology itself may be accessible to anyone. The underlying data took years to build and cannot be purchased.
A Note on Security and Governance
This comes up in every serious implementation conversation, and it should. Proprietary training data needs to stay proprietary. Every engagement we run includes SOC 2 compliance, HIPAA certification where applicable, GDPR alignment, and deployment within the organization’s own environment from the start. Building these in after the fact costs considerably more and creates more disruption than doing it right initially.
The Window to Build This Is Now
The organizations that will define their industries over the next decade will be the ones whose AI reflects how their business actually operates, built on institutional knowledge their competitors haven’t captured and can’t replicate. The ones that get there first will also be the hardest to catch, because the system compounds with every cycle it runs.
Generic AI will make your organization more efficient. It helps teams move faster and automates work that used to eat hours. It will also fall short of preserving what your best people know and won’t create the kind of information asymmetry that lets you move faster or serve clients better than the competition. Those outcomes come from AI grounded in your specific operational reality, built on an accurate picture of how work actually gets done.
The right starting point is an honest assessment of where critical knowledge currently lives and what would happen if the people carrying it were unavailable. That question tends to be more clarifying than any technology evaluation.
Start Building AI That Compounds
Ready to build AI that actually knows your business? Valere works with organizations across industries to design, build, and scale AI systems grounded in proprietary knowledge, delivering measurable outcomes that grow over time rather than erode as competitors adopt the same tools.
Whether you’re evaluating AI maturity across your organization, preparing for a broader transformation, or figuring out where to start, Valere brings the expertise, platform, and partnership model to move from disconnected pilots to production-grade AI infrastructure.
- A Knowledge Readiness Assessment identifying where your current AI deployments lack the institutional grounding, workflow integration, and feedback architecture needed to move from generic outputs to genuinely differentiated results
- A clear path from isolated AI experiments to a governed knowledge layer that integrates with your existing operations, encodes what your organization knows, and compounds in accuracy with every cycle it runs
- A personalized value creation roadmap covering knowledge capture priorities, phased deployment sequencing, human-in-the-loop governance, and the proprietary intelligence layer that no competitor can replicate by licensing the same tools
Start building AI that knows your business: https://www.valere.io/
Frequently Asked Questions
How does knowledge capture actually work in practice? Most engagements start with a combination of system scanning and structured interviews. The scan pulls from existing operational data, including tickets, logs, message threads, and service records, to map how work actually happens. The interviews capture the judgment and reasoning that doesn’t appear in any system. The output is a structured knowledge library that AI agents draw from, with decisions traceable back to their source.
What makes Dactic different from a DIY automation platform? Platforms like Make, Zapier, or AgentForce give you capable tools and assume you already understand your processes well enough to configure them correctly. Dactic starts with discovery rather than configuration. The Discovery phase surfaces how work actually happens before any automation is built, which is the step most DIY implementations skip and the reason most of them underperform.
What’s the difference between fine-tuning a model and knowledge grounding? Fine-tuning updates the model’s weights based on training data, which works well for domain-specific language and tone. Knowledge grounding keeps the model’s weights intact but feeds it proprietary context at inference time. For most enterprise use cases, knowledge grounding is faster to implement, easier to update, and more auditable. The right approach depends on the specific use case.
How long does it take to see results? Discovery for a focused domain typically runs four to six weeks. Early pilots within a single function generate measurable baseline data within a few months. Most organizations see meaningful productivity impact within six months of an initial deployment. The full value of the feedback loop builds over subsequent quarters as the knowledge base matures.
What happens when key employees leave before knowledge capture is complete? This is exactly the risk that makes timing important. For organizations with senior staff approaching transition, prioritizing those domains early makes sense. The process often completes in two to three weeks per domain when the team treats it as a priority rather than a background project.
Does this require replacing existing systems? No. The automation layer runs inside existing systems. Most deployments use the organization’s existing infrastructure without requiring migration. The goal is to enhance how current systems function.


