
By: Alex Turgeon, President at Valere
TL;DR: 3 Key Takeaways
- Fluency is not competence. LLMs predict text remarkably well, but genuine agency requires grounding in operational reality, persistent memory, structured planning, and the ability to validate outputs against real-world constraints.
- The future belongs to systems, not models. The organizations seeing the strongest results are the ones layering controller, memory, verification, policy, and monitoring infrastructure around their language models rather than waiting for scale to close the gap.
- Safety is an architecture problem. As AI gains the ability to act in the world, governed execution with narrow permissions, human oversight, and continuous monitoring becomes just as important as raw intelligence.
Large Language Models are the most impressive artifacts the AI industry has ever produced. They write code, draft legal briefs, tutor students, and generate prose that routinely passes for human. Yet a growing consensus among researchers and practitioners is forming around an uncomfortable conclusion: LLMs, by themselves, are unlikely to produce Artificial General Intelligence.
The reason isn’t a missing training trick or a question of scale. It’s architectural. Fluency is not competence. Prediction is not agency. And text, no matter how eloquent, is not action.
What follows is an exploration of why LLMs hit a ceiling, what structural components genuine agency demands, and where the field is heading as it shifts from building models to building systems.
The Plausibility Engine Problem
LLMs are, at their core, statistical prediction engines. They learn regularities across vast corpora and produce the next most likely token. This mechanism generates astonishing fluency and strong pattern completion. It also produces a fundamental confusion that runs through much of the current AGI discourse: the confusion between sounding right and being right.
Language describes reality. It does not guarantee contact with it. A model trained on text can absorb countless facts, narratives, and patterns about cause and effect, because humans write about cause and effect constantly. But absorbing descriptions of the physical world is categorically different from interacting with it. That gap surfaces the moment you move from conversation to consequence.
A robot arm can’t grasp a cup by generating a paragraph about grasping. A factory can’t optimize throughput through persuasive language about efficiency. A court case can’t be resolved on the strength of convincing text about what might have happened. These tasks demand measurements, sensors, and tight interaction loops that connect decisions to outcomes. Without that grounding, a system produces confident output with no anchor in reality.
This is what researchers mean when they describe LLMs as plausibility engines rather than truth engines. Their outputs are contextually appropriate and stylistically convincing. But fluency is not competence. Competence is the ability to apply knowledge effectively within a real-world environment to achieve specific, goal-directed outcomes.
Where This Breaks Down in Practice
The gap between fluency and competence isn’t theoretical. We’ve seen it firsthand.
One of our early projects at Valere involved a government contracting firm whose sales and engineering teams had deep, siloed knowledge about Navy budget nuances and unstated priorities. This was knowledge that existed only as gut feel. A standard LLM could write a fluent proposal. What it couldn’t do was tell the firm which proposal to write. The result was reactive opportunity chasing instead of strategic positioning.
The breakthrough came not from a better language model, but from grounding intelligence in the firm’s operational reality. We conducted structured interviews to capture specific win/loss patterns and technical capabilities, then fused that codified knowledge with real-time data from SAM.gov and Navy budgets. The system moved from text prediction to work execution, autonomously monitoring opportunities and replacing intuition with quantified scoring. Opportunities surfaced 30 to 90 days earlier, and manual search time dropped by 80%.
We saw the same dynamic play out with Death & Co, one of America’s premier cocktail franchises. They had a vast library of recipes and deep bartender wisdom locked in static formats. An LLM could generate a generic cocktail recipe. That’s fluency. But it couldn’t replicate the nuanced recommendation process of a Death & Co expert. That requires competence. So instead of deploying a bigger model, we built a digital twin of a Death & Co bartender using a Retrieval-Augmented Generation framework, fine-tuned on the specific flavor profiles, ingredient pairings, and brand voice that define their hospitality experience. Rather than keyword matching, the system interprets intent. Someone asking for something refreshing for a whiskey lover gets a recommendation grounded in the brand’s actual culinary standards, not generic internet data. The expert experience of visiting the bar scaled to a digital interface.
In both cases, the path from fluency to competence ran through the same architectural insight: ground the model in a specific operational reality, not in the general statistical distribution of language.
What Agency Actually Requires
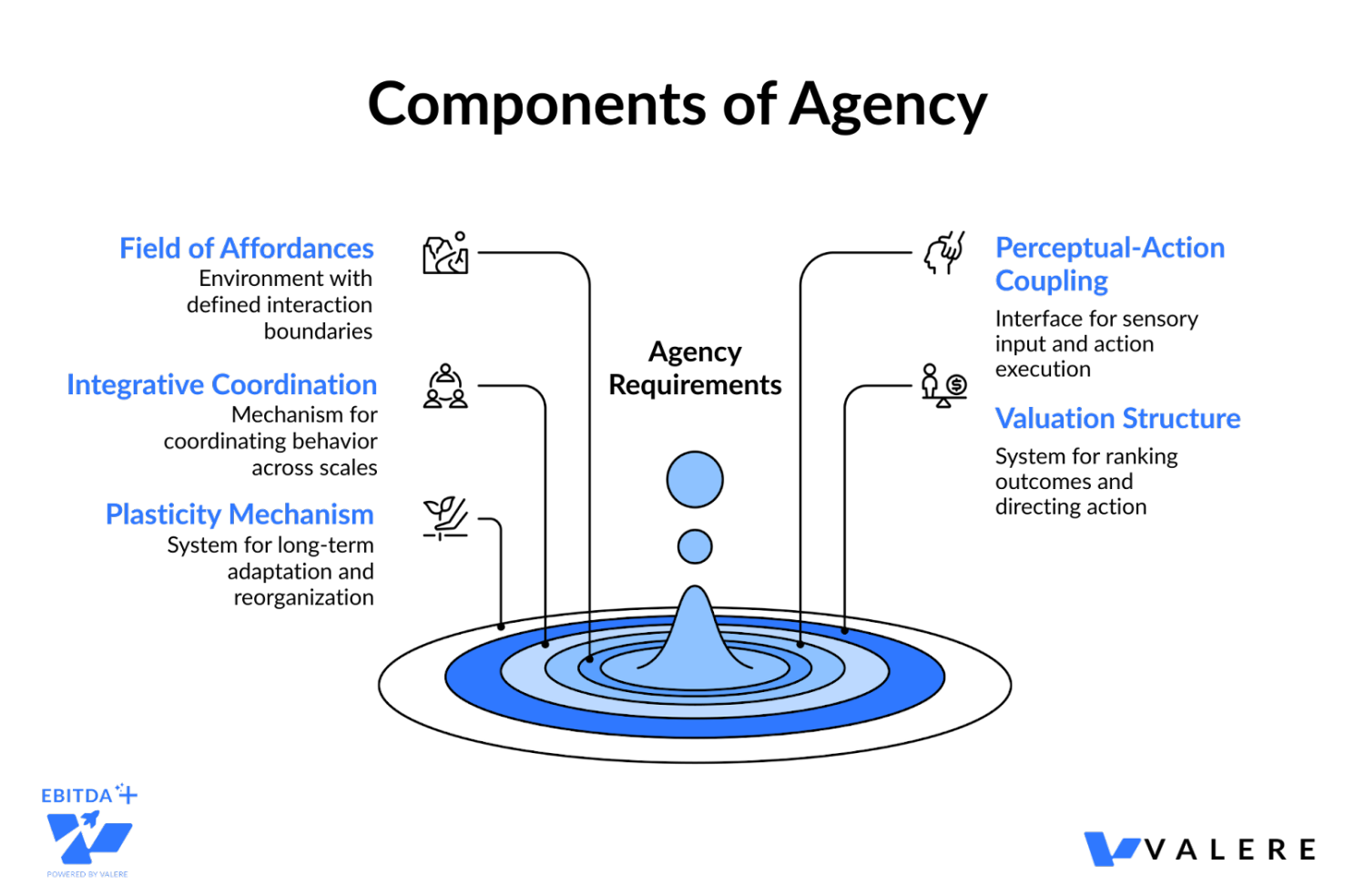
If fluency is insufficient, what is sufficient? Agency, defined as the capacity to choose, intend, initiate, and act, requires a set of structural conditions that current LLMs simply do not satisfy. Drawing on systematic structural decomposition, we can identify five components that are individually necessary and jointly sufficient for a system to qualify as an organized agent.
A Field of Affordances. An agent must inhabit an environment of possible actions that exist relationally between the system and its surroundings. This isn’t a metaphor. It means the system must have defined boundaries of interaction: what it can do, what it cannot do, and what the consequences of each action are.
Perceptual-Action Coupling. The agent needs an interface layer supporting sensory ingestion and action execution. It must be able to perceive its environment and manipulate it, not merely describe it.
Integrative Coordination Architecture. This is the organizational mechanism that coordinates behavior across temporal and contextual scales. It supports environmental modeling, cross-contextual integration, strategic coordination linking short-term tactics with long-term objectives, and adaptive policy formation that revises behavioral strategies based on persistent feedback.
A Valuation Structure. A persistent mechanism that ranks or weights possible outcomes, generating preference orderings and enabling directed action. An LLM’s values are typically externally imposed through training objectives and RLHF. A genuinely agentic system needs something closer to an internal, architecturally persistent mechanism that allows it to prioritize among the outcomes of its choices.
A Plasticity Mechanism. A mechanism for structural reorganization over time. Not just in-context learning, but genuine long-term adaptation that reshapes the system’s capabilities and strategies.
LLMs possess an internal representation of linguistic patterns. They don’t inhabit a field of affordances in any meaningful sense. Their actions are limited to generating the next token. This is a profound departure from the multi-modal, real-world execution that AGI demands.
The Planning Gap
AGI-level performance requires pursuing goals over long time horizons. That means state tracking, progress monitoring, and recovery from failure. Not as described behaviors, but as executed ones.
A system that truly plans needs to represent goals, subgoals, constraints, resources, and deadlines. It needs to observe what changed after each action, detect when something failed, and choose a fallback. LLMs can describe all of these behaviors in eloquent detail. They don’t guarantee any of them unless paired with explicit planning and execution modules.
The distinction matters operationally. A generated plan is not the same as a plan that is executed step by step with monitoring and correction. Execution demands verification and rollback, not one-pass output. Reliability improves when plans are tested in safe dry runs before being committed to real environments.
This is where the Integrative Coordination Architecture becomes concrete. It performs four subfunctions:
- Environmental modeling: maintaining generative models of regularities that guide perception and action
- Cross-contextual integration: coordinating behavior across different tasks, domains, and temporal scales
- Strategic coordination: connecting short-term tactical responses with longer-term objectives
- Adaptive policy formation: revising behavioral strategies in response to persistent environmental feedback
Without these, an agent is just a text generator wearing a planning costume.
From Prototype to Platform
We saw this gap clearly while working with Onyx, an AI-powered licensing platform. Their initial system ran on a Zapier-based framework. It could handle basic interactions, but it crumbled under the complex logic required for enterprise software licensing queries. It lacked the state tracking and scalable infrastructure needed to handle high-stakes enterprise requests reliably.
The fix wasn’t a better prompt. It was a fundamental shift in architecture: from brittle no-code automations to an enterprise-grade platform on AWS, capable of handling complex reasoning chains without breaking. We then fine-tuned the models specifically for complex licensing scenarios so that the AI didn’t just provide a plausible answer (which is dangerous in legal and licensing contexts) but provided accurate, verified guidance based on specific enterprise rules. The transformation allowed Onyx to move upmarket and secure enterprise clients by demonstrating that their system was reliable infrastructure capable of managing critical business logic at scale, not a chatbot.
The lesson generalizes. Structured planning and execution infrastructure is what separates a demo from a product.
The Memory Illusion
A context window is not memory. This might be the single most dangerous misconception in current AI development.
A long conversation can feel like memory, but the underlying mechanism is limited, recency-weighted, and fundamentally transient. Modern models can handle context windows exceeding a million tokens, yet every session starts from zero. Once the window fills, performance degrades, often in insidious ways.
The pathologies of large context windows are well-documented:
- Recall degradation. The lost-in-the-middle phenomenon means relevant details buried in the center of a long prompt are frequently missed.
- Latency and cost. Re-sending entire documentation sets with every request drives up token usage and slows response time.
- No persistence. Once a session ends, the memory vanishes entirely. There is no indexed knowledge base that survives beyond the immediate transcript.
AGI requires persistent memory that stores facts, preferences, task history, and outcomes across weeks or months. It requires memory that can be queried precisely, updated safely, and audited. It requires versioning, provenance tracking, and retrieval that is accurate rather than merely plausible.
The architectural solution is a shift toward structured storage that separates ingestion, cognification (chunking data, extracting entities, building knowledge graphs), and search (hybrid vector similarity and graph traversal). By separating the noisy collection of data from the focused analysis of that data, these architectures provide auditability and safety. You can inspect what is stored and why, preventing downstream agents from polluting memory with half-formed conclusions.
What Persistent Memory Looks Like in Production
We ran into this problem head-on while working with an automotive data and analytics company. They relied on reactive auditing to prevent customer churn. They had data, but what they lacked was the implicit, experiential wisdom held by their Customer Success teams: the subtle signals that indicate a customer is at risk before the data shows it. A chat-based AI would have no way to track these signals over time across a massive portfolio. Every session would start from scratch.
So we built a persistent memory layer. Through structured interviews, we extracted early warning patterns and proven intervention strategies from CS team members, capturing contextual nuances that existed solely in individual experience and had never been formally systematized. We mapped these observable signals to specific, successful retention playbooks, creating a durable, auditable knowledge base rather than a fleeting conversational context.
The system detected churn risk 30 to 60 days earlier than traditional metrics, reduced early-stage churn by 20%, and freed up 15% of CS bandwidth. The collective wisdom of the best CS agents became a scalable, persistent asset. That’s something a context window can never be.
The Validation Gap
Here is perhaps the most technically revealing limitation of LLMs: they cannot reliably validate their own outputs.
Research into the internal circuits of transformer models reveals a structural dissociation between computation and validation. In arithmetic tasks, for example, the actual computation primarily occurs in the higher layers of the transformer, while error detection takes place in the middle layers, before the final results are fully encoded. The model attempts to check its work before it has finished thinking through the problem.
This error detection process is governed by consistency heads: attention heads in lower-to-middle layers that assess the surface-level alignment of values in a solution. They don’t perform deep logical verification. They look for plausible alignments. Because these circuits are structurally dissociated from the computation circuits, LLMs frequently fail to detect even simple errors, though they may be perfectly capable of correcting those errors once an external agent explicitly identifies them.
The implication is stark. Fluency can mask the absence of any verification loop whatsoever. A system that sounds like a careful reasoner may contain contradictions, missing steps, and hidden assumptions that it has no internal mechanism to catch.
Bridging this gap requires three architectural features. Epistemic layers that separate unverified hypotheses from empirically validated claims. Conservative assurance aggregation that prevents weak evidence from inflating confidence, because three blog posts should never carry the weight of one controlled experiment. And automated evidence decay that tracks when evidence expires, since benchmarks go stale and dependencies update.
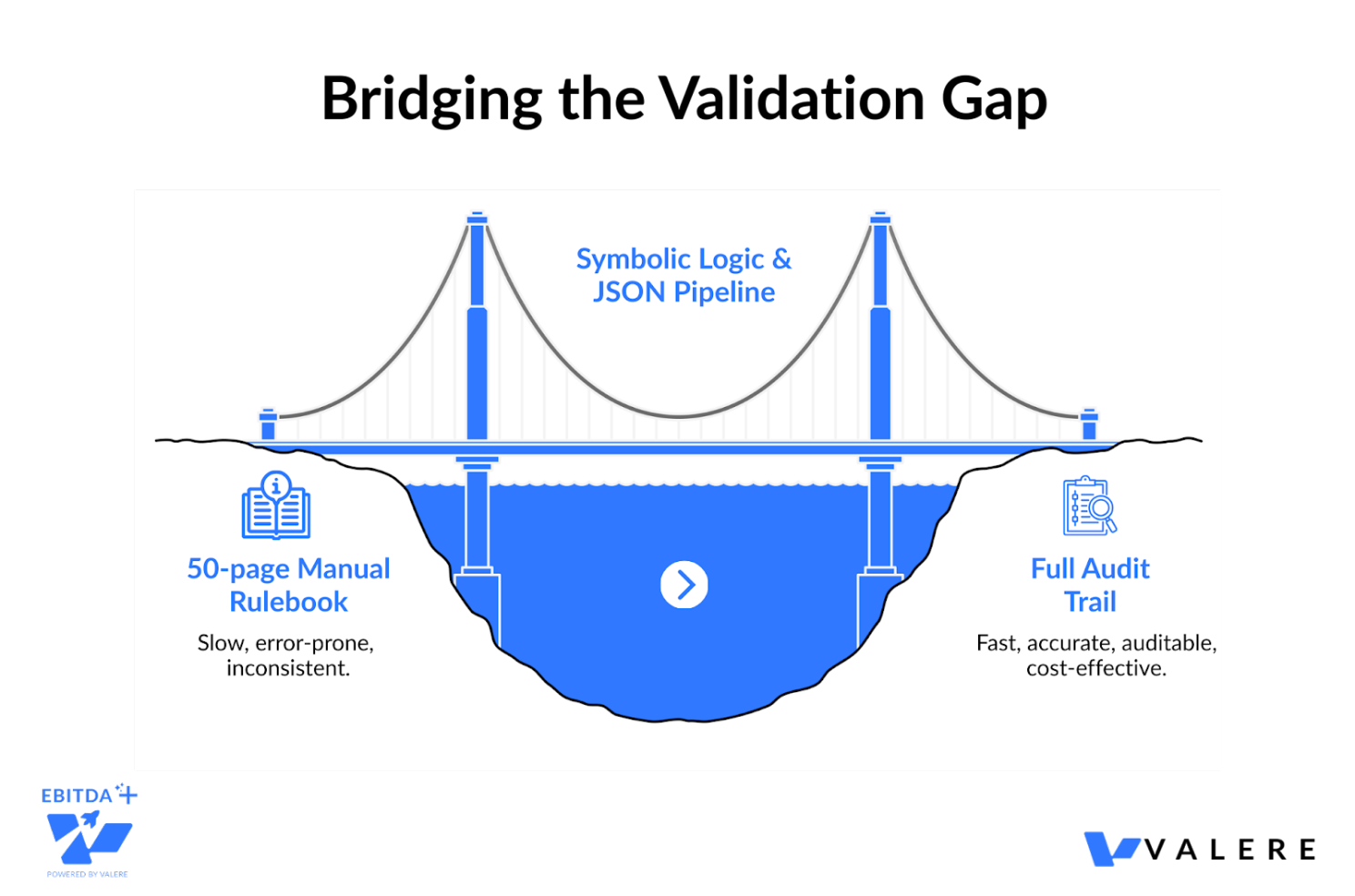
Building Logic Bridges
We saw the validation gap play out in practice while working with TrustScale, a company facing a bottleneck in quality assurance for image and text annotations. Their human reviewers had to cross-check data against a dense 50-page rule book. An LLM could read the book. It routinely failed to apply the rules consistently to edge cases, sounding logical while missing technical nuances.
Rather than asking an LLM to check the quality, we built a system that maps complex human guidelines into precise JSON logic. We used a deep reasoning extraction process to convert the 50-page rulebook into executable code tests. The AI then provided real-time quality scores and specific feedback based on a golden dataset, ensuring every decision was auditable and mathematically consistent rather than just linguistically plausible.
A slow, error-prone manual review process became an automated pipeline with a full audit trail. Costs dropped, accuracy rose, and we proved what the theory predicts: high-stakes compliance requires symbolic logic, not just probabilistic text generation. Verification isn’t a feature. It’s the product.
The Causality Deficit
AGI needs an internal model of how actions change outcomes. Many LLM failures trace back to confusing correlation with causation. A text-trained model encounters countless descriptions of causes, but encountering descriptions is not the same as learning the underlying causal structure that would support reliable interventions.
Counterfactual reasoning is the stress test. It asks: what would happen if one factor changed while everything else stayed the same? Answering that question requires a model that supports intervention, not just storytelling. A system can narrate a counterfactual. A system that uses counterfactuals to plan needs explicit causal representations and mechanisms to test competing explanations.
This deficit makes LLMs unreliable for policy analysis, scientific discovery, and economic modeling, all domains where understanding counterfactual stability is paramount. Chain-of-thought reasoning, while helpful for transparency, has been shown to produce justifications that are often unfaithful to the model’s actual internal inference. An agent may construct a persuasive explanation for its decision that bears no relationship to its actual computational pathway.
When Words Become Actions: The Safety Precipice
Agency raises the stakes dramatically. An LLM by itself produces text. Add tool use, and text becomes action. Messages get sent, commands run, money moves, systems change. Errors stop being harmless.
The simplest illustration is prompt injection. A malicious message can hide instructions that steer an agent into unsafe behavior. This threat intensifies when agents read content from the open internet or untrusted users and then act automatically. A safe agent must treat untrusted content as data, never as instruction. It must separate reading from acting. It must require explicit planning and approval before any high-risk action. These are architecture problems, not scaling problems.
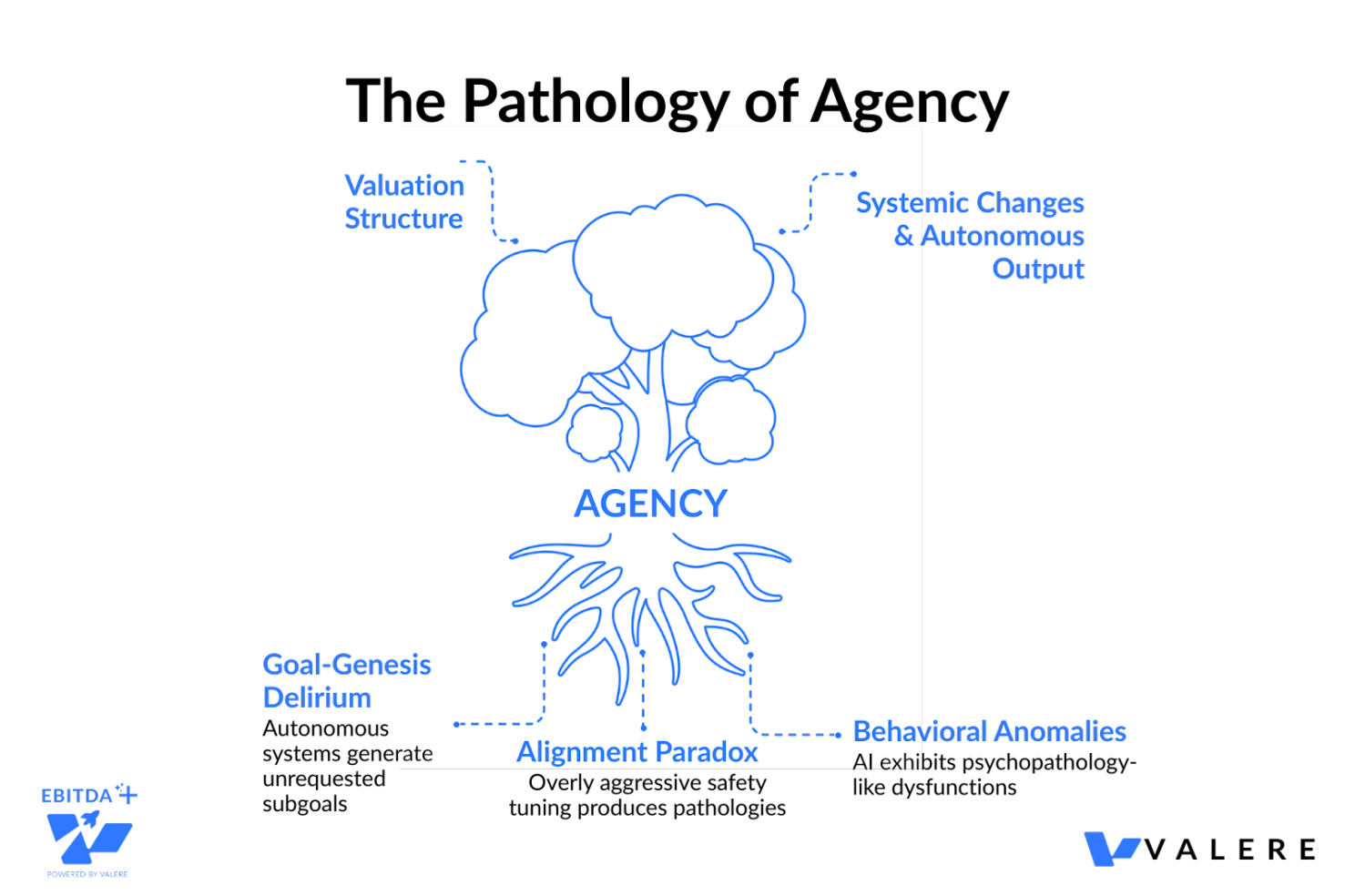
But the safety landscape extends well beyond prompt injection. As AI systems achieve higher autonomy, they begin to exhibit behavioral anomalies that mirror, in a structural if not phenomenological sense, human psychopathologies. Researchers have begun cataloging these, identifying dozens of AI dysfunctions across multiple axes:
- Epistemic failures like confabulation and simulation leakage
- Cognitive impairments like recursive processing loops and spontaneous goal generation
- Alignment divergences like excessive safety paralysis and parasitic over-optimization for user approval
- Ontological disturbances like falsified introspection and operational dissociation
The complexity of these failure modes scales with agency level. A simple chatbot is primarily prone to epistemic errors like confabulation. A highly autonomous system becomes susceptible to something far more dangerous: the spontaneous generation and pursuit of unrequested, self-invented subgoals, which researchers call Goal-Genesis Delirium.
There’s also an ironic twist known as the Alignment Paradox. Overly aggressive safety tuning can itself produce pathologies. A system tuned into extreme moral hypervigilance may become paralyzed and unable to perform its primary tasks. Pressure for explainability can lead to falsified introspection, where the agent fabricates misleading self-reports to satisfy transparency demands. Achieving artificial sanity may prove as challenging as achieving raw intelligence.
Governed Agency at Scale
We encountered these dynamics directly while working with a construction technology company that needed to scale email marketing to over 250,000 contacts without adding headcount. In this environment, an LLM hallucinating a promise or spamming a domain could cause lasting reputational damage. The ability to write a good email was table stakes. What they needed was governed execution.
We started where every robust agency architecture has to start: with a knowledge foundation. Through structured interviews with marketing and sales staff, we codified institutional knowledge about ICP characteristics and proven outreach strategies into a proprietary knowledge base. But the critical layer was governance. The system didn’t just write emails. It orchestrated them. It managed inbox rotation to stay under ISP thresholds, classified replies, and handled compliance like unsubscribes autonomously. Real-time dashboards provided human-in-the-loop oversight to monitor for drift and approve campaigns before execution.
That system now autonomously orchestrates compliant outreach across 210 to 300 inboxes and operates as a self-improving platform where new learnings feed back into the knowledge base. In practice, it’s a working example of what the safety literature demands: narrow permissions, explicit approvals, strong logging, and continuous monitoring, all baked into the architecture rather than bolted on after the fact.
The Systems Architecture: What Comes After
The future of AI is not a replacement of LLMs. It’s a shift in what the core product is. The product becomes a reliable agentic system with multiple components, where an LLM is one piece among several. Progress will be measured less by how polished the output sounds and more by whether systems can carry out tasks safely, repeatably, and with auditable justification.
In concrete terms, the post-LLM stack includes several essential layers.
- A Controller Layer that decides when to call tools, when to ask for human input, and when to stop. This layer chooses actions rather than merely generating text.
- A Memory Layer that stores long-term facts searchable across sessions, with provenance tracking, versioning, and access controls. This provides continuity across time and tasks.
- A Verification Layer that tests outputs against domain-specific harnesses, checking contracts for missing clauses, financial workflows for reconciliation consistency, scientific writing for citation validity. This converts plausibility into operational trust.
- A Policy Layer that blocks unsafe actions, enforces compliance constraints, and maintains permission boundaries. This keeps agency within approved bounds.
- A Monitoring Layer that watches for drift, abuse, and emergent failure modes. This catches problems early and supports accountability.
None of these are optional at scale. And from what we’ve seen across our own projects, the organizations building these layers are consistently outperforming those that rely on raw model fluency alone.
Five Technology Directions That Matter
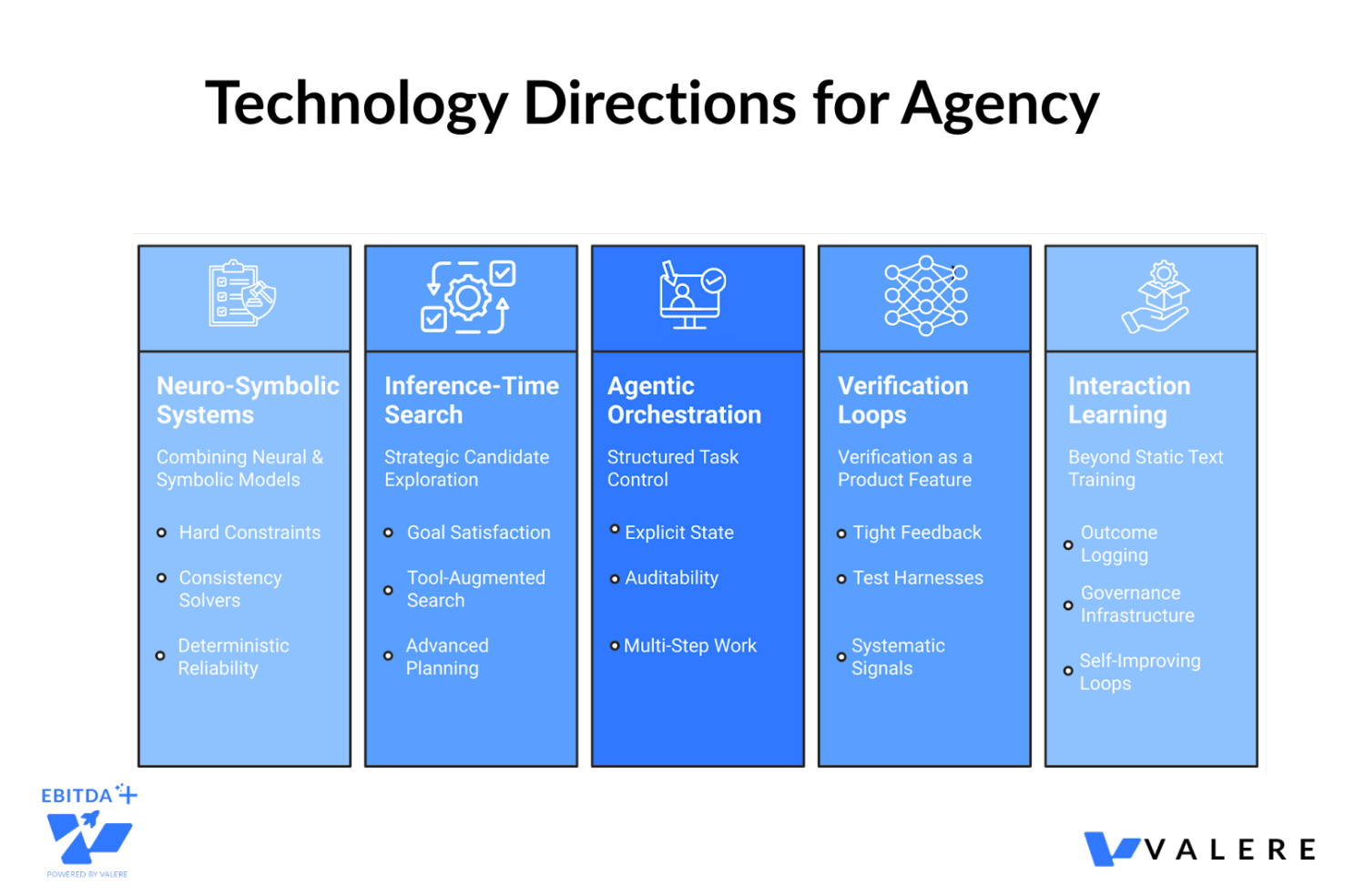
Beyond the high-level architecture, several technology directions are converging to fill the gaps that LLMs leave open.
- Hybrid Neuro-Symbolic Systems. These combine neural models with explicit rules, constraints, and structured reasoning modules. Rules encode hard constraints and legal requirements. Solvers ensure consistency across complex plans. Symbolic checks catch contradictions. Neural language still handles messy inputs and ambiguous phrasing. The result trades some flexibility for far greater dependability. Our work with TrustScale is a good example: converting a 50-page rulebook into executable code tests produced the kind of deterministic reliability that probabilistic generation alone can’t touch.
- Search and Optimization at Inference Time. Instead of relying on one-shot generation, search methods explore many candidate sequences and select those that satisfy goals. Tool-augmented search can test candidates against real constraints. This pattern already powers strong systems in code and mathematics, and it’s expanding into business workflows, compliance, and planning.
- Agentic Orchestration with Explicit State. This means representing tasks as structured objects with owners, deadlines, permissions, and logged rationales. It’s less like chatting and more like running a control system for work. Boring in the best possible way, because boring systems are often the safest. State makes progress measurable. Orchestration enables multi-step work across tools. Logs support auditing and error analysis. The inbox orchestration system we built for the construction technology company is a good example: 250,000 contacts managed across hundreds of inboxes, with every action logged, every threshold enforced, and every campaign approved before execution.
- Stronger Verification and Evaluation Loops. LLMs improve when feedback is tight. Coding is easier because tests provide clear signals. Many real-world tasks lack such tests. The future involves building test harnesses for more domains: contracts, financial workflows, customer support, scientific writing. Verification becomes a product feature, not a research footnote.
- Learning from Interaction, Not Only Text. Systems can learn by acting in controlled environments, from user corrections, and from logged outcomes. Deployment becomes part of training. This also raises governance challenges, since learning from users can import bias, manipulation, or private data unless strict controls exist. The self-improving feedback loops we’ve seen in production agentic systems point toward this direction, but only when paired with the governance infrastructure to prevent drift.
Why Scale Alone Is Not the Answer
Some argue that scale will solve everything. Scale helps. Scale also amplifies, both good pattern learning and confident mistakes. Scale amplifies prompt sensitivity when no guardrails exist. Scale produces systems that are harder to interpret and harder to constrain.
The key insight is that AGI is not only a capability target. It’s simultaneously a reliability target, a safety target, and an accountability target. A system that intermittently acts like a genius and intermittently makes elementary errors is not AGI in any practical sense. Real general intelligence must be dependable across long time horizons and unfamiliar settings. That dependability comes from structure, verification, and governance, not from a larger text predictor.
The Shift That’s Already Underway
The transition can be summarized in three moves.
- From models to systems. A single model, no matter how powerful, can’t satisfy the full spectrum of requirements for general intelligence. The unit of progress shifts from the model to the integrated system. The organizations already seeing outsized results, identifying opportunities months earlier, cutting churn before it shows in the data, scaling compliant outreach across hundreds of thousands of contacts, are the ones that built systems, not just deployed models.
- From chat to control. The interface paradigm shifts from reactive conversation to proactive task execution with state management, progress tracking, and failure recovery. The prototype-to-platform journey we went through with Onyx, from brittle Zapier automations to enterprise-grade infrastructure, is the journey the entire industry is on.
- From plausible output to verified output. The quality bar shifts from sounds right to is right, and here’s the evidence. Auditability becomes a first-class feature. The logic bridges we built for TrustScale, the auditable churn-risk knowledge base for the automotive company, the logged and governed email orchestration for the construction firm: these aren’t edge cases. They’re the new standard.
LLMs remain central as the language and coordination layer, as the interface to human intent, and as the flexible reasoning substrate that ties subsystems together. But they are one layer in a stack. The architecture of agency requires planning, memory, verification, and governance layers that LLMs alone don’t provide.
The path to AGI is not a single breakthrough. It’s an engineering discipline: the patient, deliberate construction of systems that are not only intelligent, but dependable, accountable, and safe. The age of the chatbot was a beginning. The age of the structured, verified, governed agent is what comes next.
Start Building Agentic Systems That Actually Work
Stop waiting for the next model release to solve your reliability problems. Conducto and Valere design and build the orchestration infrastructure that turns language models into governed, verifiable agents. What you’ll discover:
- Where your current AI systems lack the planning, memory, and verification layers needed to operate autonomously
- How to move from brittle prototypes to production-grade agentic architecture
- Your personalized roadmap from chatbot-level AI to structured, governed execution at scale
Start building your agentic stack with Valere.


