
By: Alex Turgeon, President at Valere
TL;DR: 3 Key Takeaways
- Companies are failing at AI implementation not from lack of data but from drowning in uncurated information that causes model hallucinations, compliance risks, and costs organizations an average of $13 million annually in poor data quality.
- Strategic forgetting through agentic AI and RAG systems acts as an enterprise immune system, automatically identifying and removing outdated regulations, expired PII, and toxic legacy data that poison machine learning models and create legal liability.
- Organizations that operationalize data hygiene see 40%+ performance improvements, lower cloud infrastructure costs, reduced cyber insurance premiums, and AI-ready systems trained on high-quality curated datasets instead of petabytes of digital exhaust.
For the last decade, the tech industry convinced everyone that data was the new oil. The logic was seductive in its simplicity. Store everything. Log every interaction. Archive every Slack message and keep every version of every PowerPoint deck. We were told that storage was cheap and that someday, some magical algorithm would descend from the cloud to turn those petabytes of digital exhaust into pure profit.
We are now living through the consequence of that advice.
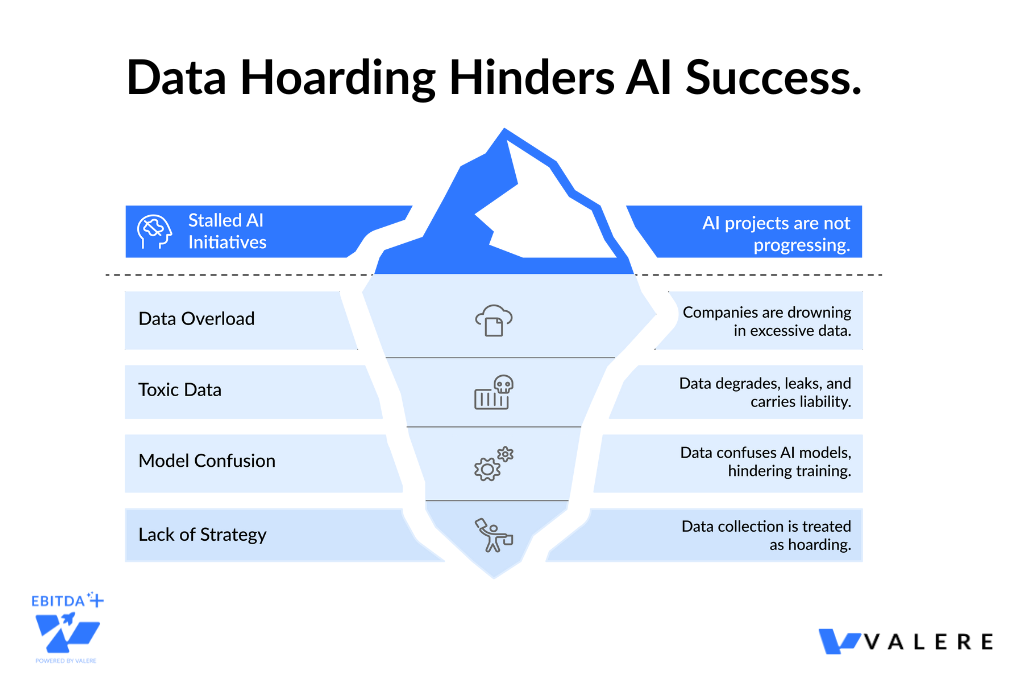
At Valere, we see this constantly when we step in to rescue stalled AI initiatives. Companies aren’t failing because they lack data. They’re failing because they’re drowning in it. They’ve treated data collection like a hoarding disorder rather than an asset strategy.
The reality is that for a modern AI-first organization, data is not always an asset. As security expert Bruce Schneier famously argued, data is often a toxic asset. It degrades over time. It leaks. It carries legal liability. And most critically for those of us building production AI systems, it confuses the models we’re trying to train.
If you want to unlock real value from AI, the kind that actually expands EBITDA rather than just generating press releases, you need to stop obsessing over how to remember more. You need to learn how to strategically forget.
The High Cost of Digital Hoarding
Most mid-market executives I talk to treat their data lakes like a safety blanket. They keep 15 years of customer logs just in case.
Let’s look at the P&L impact of that decision.
The direct costs are obvious. You’re paying monthly cloud storage fees for terabytes of data that nobody has queried since the Obama administration. But the hidden costs are where the real damage lies. Gartner estimates that poor data quality costs the average organization nearly $13 million annually.
Why? Because bad data breaks automation.
When we build agentic AI systems, those agents need clear, high-signal context to make decisions. If you feed an autonomous agent a slurry of outdated customer records, biased historical hiring data, and deprecated API keys, you don’t get intelligence. You get hallucinations.
We saw this play out publicly with Zillow’s iBuying algorithm, which choked on historical data that failed to account for rapid market shifts, leading to a $500 million write-down. We saw it with Taco Bell’s AI drive-thru, where models trained on noisy datasets were reportedly easily confused, leading to chaos and frustration.
I’ve seen the same pattern in our own work. A large construction company approached us with over 10TB of building codes, engineering specifications, and SQL databases accumulated over decades. Their engineers were drowning in PDFs, many containing outdated or conflicting regulatory information. When they tried to build an AI assistant to navigate this corpus, the system hallucinated constantly. It cited deprecated codes, contradicted current safety standards, and created genuine liability risk.
The problem wasn’t their AI. It was their refusal to forget.
These weren’t technology failures. They were curation failures.
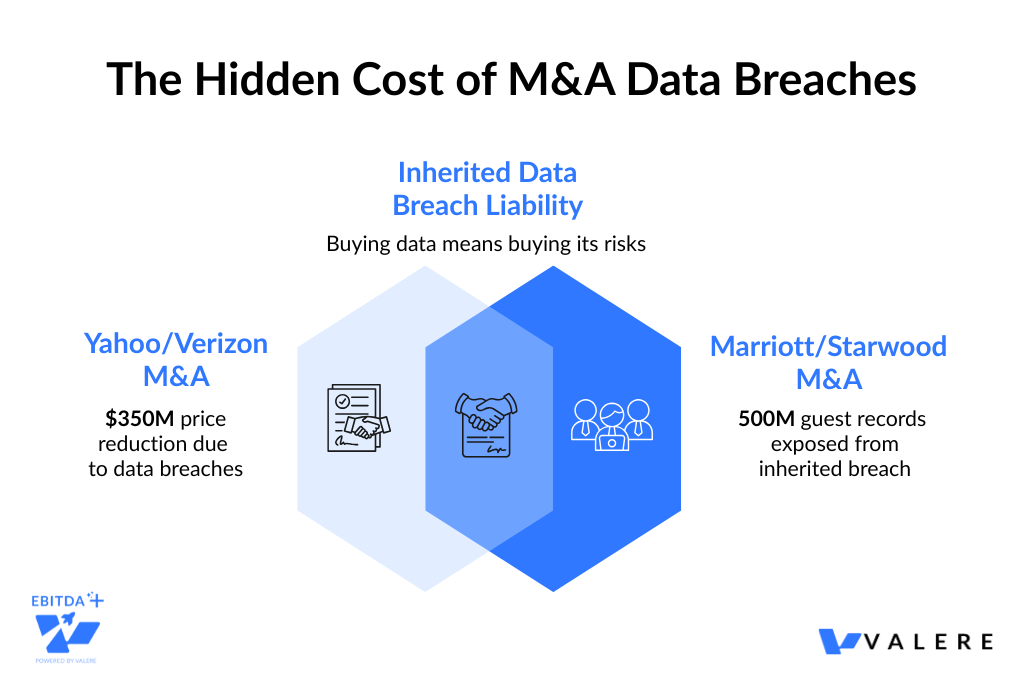
The Hidden Balance Sheet: Data Liability in M&A
Mergers and Acquisitions are high-stakes events where valuations are debated down to the last penny. Yet, there remains a glaring blind spot: the toxicity of the target company’s data. Historically, due diligence focused on “how much data do you have?” rather than “how much liability is hiding in your servers?”
This oversight has led to significant value destruction.
The failure to treat data privacy and cybersecurity as foundational components of valuation is a fiduciary oversight. A target company's data practices can act as a "poison pill," dormant until the deal is signed.
Case Study: The Yahoo/Verizon Price Correction
The acquisition of Yahoo by Verizon stands as a canonical example. In 2017, Verizon agreed to acquire Yahoo’s core internet business. Then it was revealed that Yahoo had suffered massive data breaches affecting billions of accounts.
The financial impact was immediate. Verizon, originally poised to pay roughly $4.83 billion, negotiated a price reduction. The final discount agreed upon was $350 million, a roughly 7% reduction in the total deal value applied effectively overnight due to data toxicity.
Case Study: Marriott and the Starwood Legacy
Marriott acquired Starwood Hotels & Resorts in 2016 for $13.6 billion. Two years later, Marriott discovered that the Starwood guest reservation database had been compromised since 2014, two years before the acquisition took place.
The breach exposed the records of nearly 500 million guests. The critical failure here was in the IT due diligence and post-merger integration. Marriott inherited Starwood’s “Dark Data” (old reservation logs and unpatched systems) and integrated them into its own network.
The result was a massive regulatory backlash and reputational damage. The Marriott case illustrates a chilling reality: you buy the data, you buy the breach. If Starwood had practiced “Strategic Forgetting” by purging old reservation data after a set period, the scale of the breach would have been significantly smaller.
Quantifying the Risk
To address these risks, the industry is moving toward quantitative models like Cyber Value-at-Risk (VaR) and FAIR (Factor Analysis of Information Risk). These frameworks attempt to translate vague technical risks into hard currency terms.
A company that can demonstrate it only holds the data it needs, that it has automated deletion protocols, and that its AI models are trained on legally cleared, sanitized datasets commands a higher multiple. Strategic Forgetting is not just a security measure; it is a valuation driver.
Strategic Forgetting as a Capability
Strategic forgetting isn’t about blindly hitting delete. It’s about building intelligent systems that decide what an organization should un-know.
This is a shift from passive storage to active risk management. A strategic forgetting system functions like an immune system for your enterprise. It constantly scans your digital estate for toxicity.
Here’s what it looks for:
- Harmful Legacy Knowledge: That PDF from 1998 detailing a loan approval process that’s now illegal? It’s sitting in your SharePoint, waiting to be ingested by your new RAG bot. If the bot reads it, the bot will act on it.
- Drifting Models: Financial scoring systems trained on economic conditions from five years ago aren’t just useless. They’re dangerous. They encode a world that no longer exists.
- Radioactive PII: Customer data that has exceeded its retention limit. Under GDPR or CCPA, this isn’t just clutter. It’s a lawsuit waiting to happen. If you can’t prove you deleted it, you’re liable.
- Security Time Bombs: We frequently find hard-coded credentials for employees who left the company three years ago buried in old code repositories.
We dealt with this recently on a project for an AI platform for government contractors. In the world of federal procurement, a single non-compliant clause in a bid document can disqualify you from a $50 million contract. Worse, submitting proposals with outdated regulatory language or unauthorized data can create legal exposure.
The platform we built runs on AWS GovCloud with document intelligence and automated compliance checks. Think of it as an immune system for the bid process. The system doesn’t store every past proposal just in case. It actively identifies gaps, flags non-compliant data, and filters out toxic legacy language before submission. Win rates increased by over 40% because the AI isn’t being poisoned by accumulated noise.
The Solution: Agentic AI for Cleanup
You can’t solve this problem with human labor. You can’t hire enough interns to read through 50 million files and decide which ones are risky.
This is where agentic AI shines.
Unlike a rigid script that follows simple conditional logic, an autonomous agent can reason about content. The systems we’re building act as digital stewards. They crawl through storage buckets, model registries, and data catalogs to build a knowledge graph of your organization’s memory.
They evaluate artifacts based on a few key criteria:
- Utility: Has anyone actually used this file in the last 18 months?
- Risk: Does this contain sensitive PII or toxic language?
- Entanglement: If we delete this, what breaks? Which models were trained on it?
Once the agent analyzes the landscape, it doesn’t just send you a report. It proposes action.
For that construction company I mentioned, we didn’t try to feed 10TB of unrefined data into an LLM. That would be like pouring uranium ore directly into a reactor. Instead, we implemented an internal RAG system that acts as a curation layer. When an engineer asks a question about a specific building code, the system retrieves only the precise, current citations needed. It effectively forgets the 99.9% of irrelevant or outdated material for that interaction.
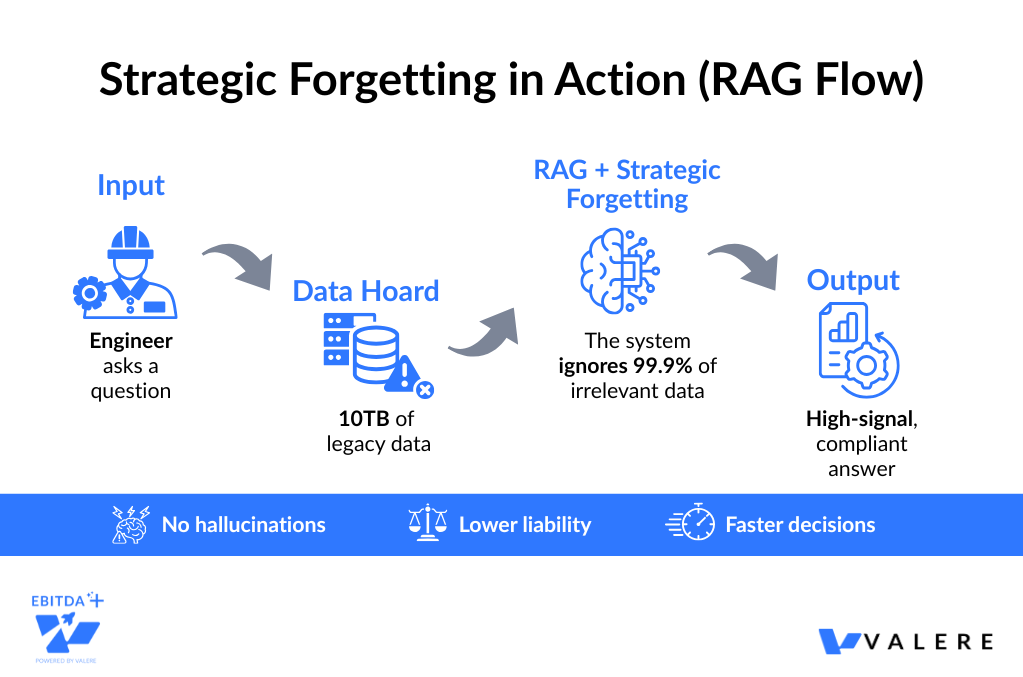
We also enforced strict Active Directory role-based access. The AI only recalls information the specific user is authorized to see, preventing both data leakage and the liability of unauthorized employees accessing regulated documents.
The agent might flag a dataset for immediate deletion because it’s high-risk and low-value. It might recommend moving old compliance documents to a cold, encrypted archive where they can’t confuse your active AI models. Or, in more advanced cases, it might trigger machine unlearning protocols.
The Technical Edge: Machine Unlearning
For technical leaders and PE operating partners, this is the most interesting frontier.
Deleting a row in a database is easy. But how do you make an AI model forget a specific data point it has already learned? If a customer exercises their right to be forgotten, you usually have to retrain the entire model from scratch. That’s slow and expensive.
We’re now seeing the rise of machine unlearning techniques, like SISA training. SISA stands for Sharded, Isolated, Sliced, and Aggregated. This allows us to retrain only a tiny slice of the model to remove specific data points.
It turns compliance from a massive engineering headache into a routine, automated process. It allows you to offer privacy as a feature, not just a legal obligation.
Operationalizing the Crawl, Walk, Run Approach
At Valere, we don’t believe in big-bang transformations. We believe in shipping value. If you want to implement strategic forgetting, follow a standard maturity curve.
- Crawl: The Inventory – Don’t delete anything yet. Just turn on the lights. Deploy agents to scan your environment and tag data. Build a heat map of your toxicity. You’ll be shocked at what you find.
- Walk: Human-in-the-Loop – Have the agents flag items for review. They might find 5,000 files containing social security numbers in a public marketing folder. A human reviews and approves the deletion. The agent learns from this feedback.
- Run: Autonomous Sanitation – Once the agents have proven their accuracy, take the training wheels off. Let the system continuously groom your data lake. Let it archive old projects and unlearn stale data automatically.
I saw this progression play out with an AWS Partner and health platform we work with. They had a massive database of supplements and health conditions, millions of data points that practitioners needed to navigate. The traditional approach would be to give users access to everything and let them search. That’s hoarding disguised as empowerment.
We moved them to an AI RAG platform that embodies strategic forgetting. When a practitioner looks up treatment options for a specific patient condition, the system doesn’t overwhelm them with the entire database. It selectively retrieves and synthesizes only the data relevant to that specific case, essentially forgetting millions of irrelevant data points in that moment. The result is a clear, hallucination-free treatment recommendation. Signal without noise.
The ROI of Forgetting
For my Private Equity friends, this is your value creation lever.
When you’re looking at a target company, data hygiene is a proxy for operational maturity. A company hoarding petabytes of dark data is carrying a massive off-balance-sheet liability. They’ll face higher cyber insurance premiums, higher cloud infrastructure costs, and a much harder time deploying AI.
Conversely, a company that has operationalized strategic forgetting is AI-ready. Their cloud bills are lower because they aren’t storing junk. Their legal risk is minimized. And most importantly, their AI models work better because they’re trained on high-quality, curated data.
We need to reintroduce the human capacity for forgetting into our digital systems. It isn’t about losing knowledge. It’s about clearing away the noise so you can actually hear the signal.
Stop buying storage. Start building intelligence.
Start Your AI Journey, Strategically.
Interested in seeing where your organization’s data hoard stacks up? Our AI Maturity Assessment shows where your company stands today and what to prioritize next. What you’ll get in minutes:
- Your AI maturity score (0–5)
- Tailored recommendations for immediate impact
- A concise assessment you can bring to the next meeting
Take the assessment here: valere.io/ai-maturity-assessment/


