
TL;DR
Mid-market companies are losing $1.25 million annually over a simple two-week switch, but cost arbitrage is only half the story this week. I’ve seen clients achieve 50% accuracy improvements by migrating away from flagship models to fine-tuned alternatives, and 98% precision by abandoning LLMs entirely for vertical-specific vision models. The selection crisis isn’t about finding the “best” model. It’s about matching the right model to each workflow. Get this wrong, and you’re subsidizing vendor profits instead of protecting your margins.
The $1.25M Mistake Nobody’s Tracking
Your engineering team defaults to the model they know best. If they learned on GPT-4, they reach for GPT-5.2. If they love Claude’s developer experience, everything goes through Opus 4.5. This isn’t malice. It’s inertia. But inertia at scale costs real money.
Let me show you the math on a typical mid-market company:
Company Profile:
- $150M ARR, 40% gross margins
- AI features drive 30% of product value
- Processing 1 billion tokens monthly (customer support, document analysis, code generation)
The Default Approach: Route everything through GPT-5.2 because “it’s the best.“
- Cost: $1.75 input + $14.00 output per million tokens
- Monthly spend: $6.65M (assuming 60/40 input/output split)
- Annual cost: $79.8M
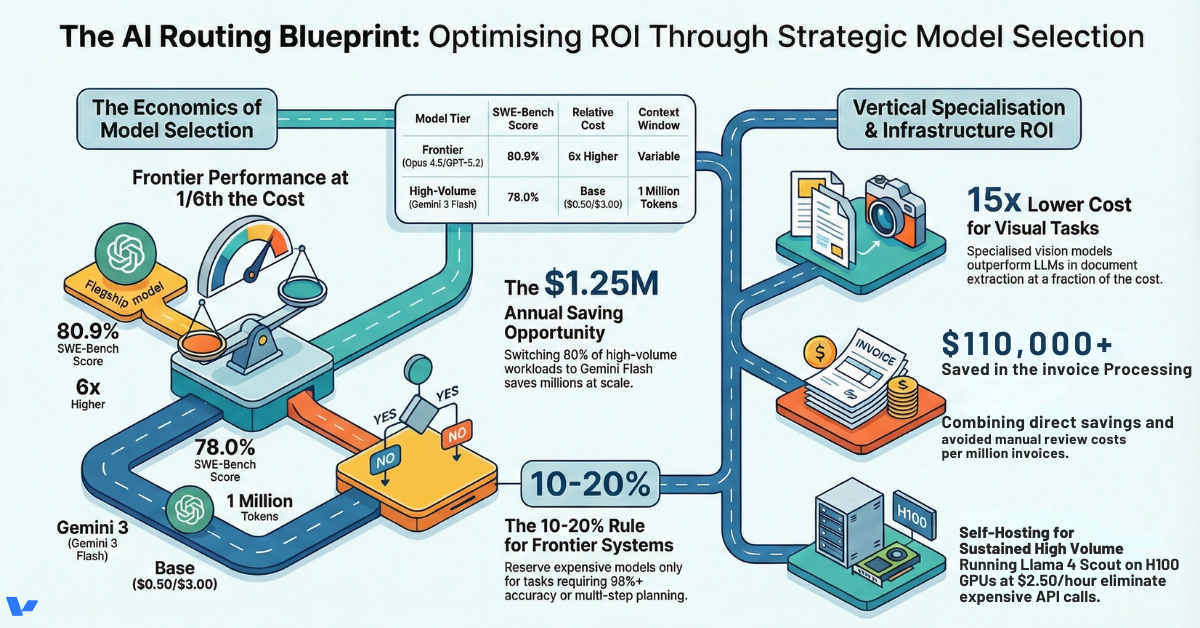
The Optimized Approach: Route 80% of routine work to Gemini 3 Flash, reserve premium models for complex tasks.
- 800M tokens through Flash at $0.50/$3.00 = $1.2M/month
- 200M tokens through Claude Opus 4.5 at $5.00/$25.00 = $2.6M/month
- Total monthly spend: $3.8M
- Annual cost: $45.6M
Annual savings: $34.2M
That’s not a rounding error. That’s the difference between hitting your EBITDA targets and missing them by double digits. And most CFOs don’t see it until the annual cloud bill arrives.
Domain-Specific Beats Generic: The Onyx Migration
Onyx came to us with a chatbot problem. They’d built it on a generic Zapier-wrapped LLM. Looked good on paper. Failed in production.
The symptoms:
- Responses customers called “technically correct but useless.”
- ~60% accuracy on commercial licensing questions (their core domain).
- Customer satisfaction stuck below enterprise thresholds.
- Couldn’t target accounts over $100M revenue because the product wasn’t reliable enough.
The diagnosis: They were using GPT-4 through a no-code wrapper. The model was fine. The architecture was the problem.
Generic models score well on broad benchmarks because they’ve seen the entire internet. But that means shallow knowledge across millions of topics. For specialized domains, commercial licensing, medical billing codes, and proprietary manufacturing processes, shallow knowledge produces confident wrong answers just often enough to destroy trust.
The fix: We migrated Onyx off Zapier to a custom AWS backend and fine-tuned the model on their proprietary licensing dataset. Not expensive pre-training from scratch. Just taking an existing model and specializing it on their specific knowledge.
The results:
- 50% improvement in response accuracy (60% → 90%+)
- 40% increase in feature implementation efficiency (freed from Zapier’s constraints)
- 30% boost in user satisfaction
- Positioned to target enterprise customers with $100M+ revenues
- Eliminated ongoing Zapier subscription costs
Here’s the lesson: A fine-tuned mid-tier model beats a generic flagship model for domain-specific work. Every time. Full case study: valere.io/case-study/onyx
Claude vs GPT vs Gemini: LLM Benchmarks That Actually Matter
I analyzed the latest LLM benchmarks across coding, reasoning, and multimodal tasks. The Claude vs GPT debate misses the point; both are overkill for 80% of tasks. Here’s what the data shows for models dominating early 2026:
Coding & Software Engineering (SWE-bench Verified)
This benchmark tests real-world GitHub issue resolution, understanding a codebase, planning a fix, and implementing it without breaking existing functionality.
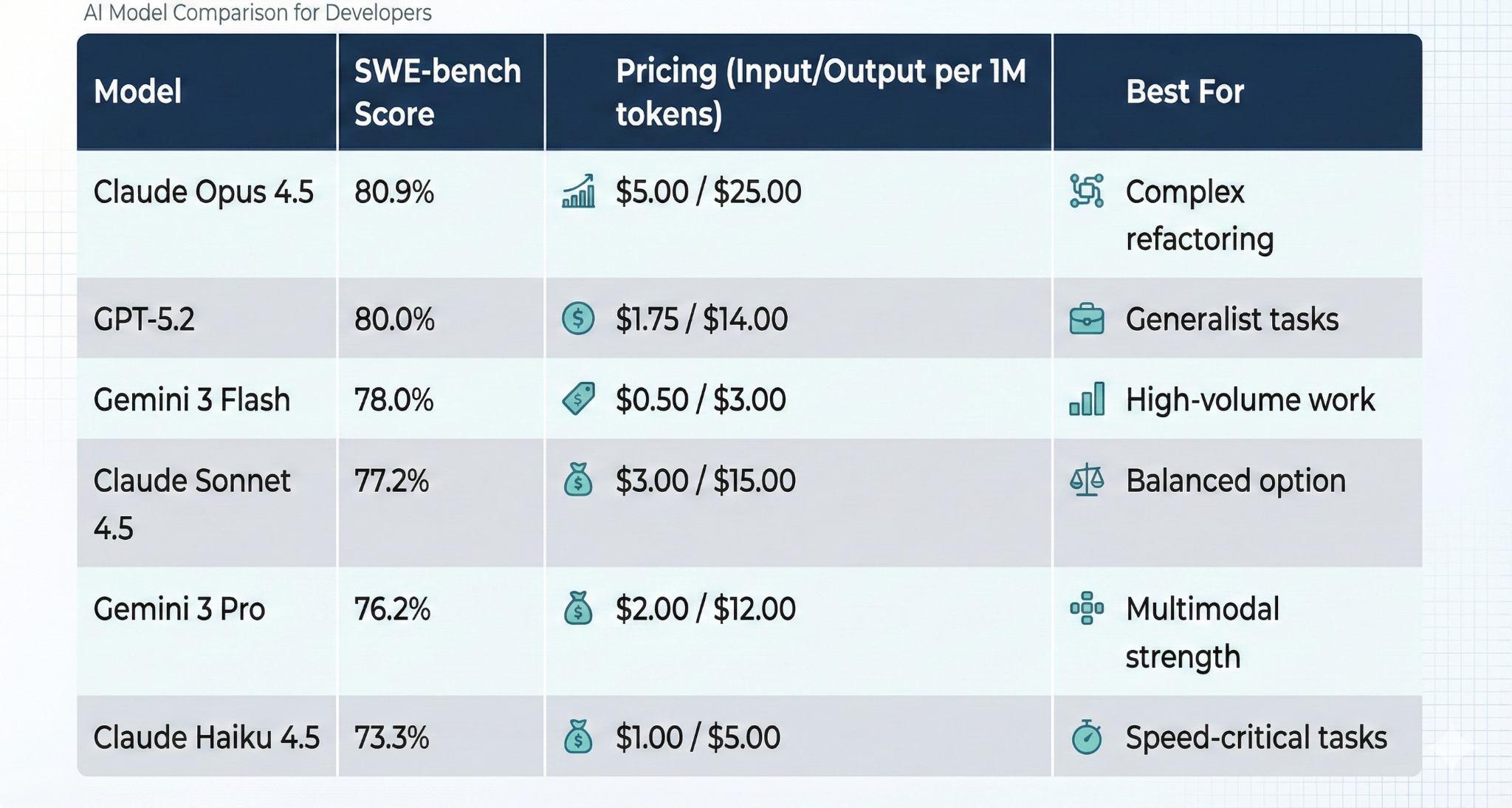
The efficiency inversion: Gemini 3 Flash outperforms its larger sibling (Gemini 3 Pro) and rivals models costing 3-10x more. For automated code generation, CI/CD pipelines, and test generation, Flash is the value leader.
When to pay premium: Claude Opus 4.5’s 80.9% justifies the cost for complex refactoring, security-critical code, or workflows where that extra 2.9% accuracy prevents costly bugs.
Reasoning & Mathematics (GPQA & AIME)
For Ph.D.-level scientific reasoning and advanced math:
- GPT-5.2: 100% on AIME 2025, 92.4% on GPQA Diamond (the gold standard for pure logic)
- Gemini 3 Pro: 91.9% on GPQA, 90.4% on AIME (excellent scientific reasoning)
- Claude Opus 4.5: 92.8% on AIME (highly capable, trails OpenAI’s flagship slightly)
Use case: Financial modeling, scientific R&D, complex actuarial calculations. The gap between best and rest justifies premium pricing when precision matters.
When conducting AI model comparison for reasoning tasks, GPT-5.2 maintains a slight edge. But for most business applications, the 1-2% difference doesn’t justify the cost premium.
Multimodal Capabilities (Vision, Video, Audio)
- Gemini 3 Pro: 81.0% on MMMU-Pro, 87.6% on Video-MMMU (Google’s native multimodal architecture dominates)
- GPT-5.2: 76.0% on MMMU-Pro (strong but trails for visual/temporal data)
- Llama 4 Scout: 69.4% on MMMU (best open-weight option for on-premise deployment)
Use case: Customer support call analysis, security footage processing, chart data extraction.
The Context Window Revolution
Context windows have exploded:
- Llama 4 Scout: 10 million tokens (entire legal libraries or codebases in one prompt)
- Gemini 3 Pro: 2 million tokens
- GPT-5.2: 400,000 tokens
For legal, pharma, or compliance-heavy verticals, Llama 4 Scout deployed in a VPC is often the only viable option. You can feed thousands of pages of case law or clinical trial data without chunking strategies or vector databases.
Llama 4 vs GPT-5.2: When Self-Hosting Makes Sense
The Llama 4 vs GPT comparison isn’t about quality. It’s about control and economics at scale. When to use GPT-5.2 (API):
- Variable workloads (10M-500M tokens/month)
- Testing and prototyping phases
- When you need the absolute best reasoning performance
- Teams without ML infrastructure expertise
When to use Llama 4 Scout (self-hosted):
- Sustained high volume (1B+ tokens/month)
- Data sovereignty requirements (HIPAA, defense, banking)
- Need for 10M token context windows
- Mature ML ops teams
The economics: Running Llama 4 Scout on a single NVIDIA H100 with INT4 quantization looks like this:
- GPU rental cost: ~$2.50/hour
- Throughput: 110-147 tokens/second
- Effective cost: ~$0.08-$0.20 per million tokens (at high utilization)
Compare to GPT-5.2 at $1.75/$14.00 per million tokens. Break-even point: Around 200-300M tokens/month of sustained usage.
The hidden costs of self-hosting:
- Engineering time managing infrastructure
- GPU availability and failover
- Model updates and version management
- Monitoring and optimization
For most mid-market companies, managed APIs like Gemini Flash or GPT-5 mini offer better total cost of ownership until you hit massive scale.
Exception: If you’re in a regulated industry where data cannot leave your VPC, Llama 4 Scout is often the only option. The TCO comparison becomes irrelevant when compliance mandates self-hosting.
AI Model Comparison Framework: What to Use When
AI model comparison shouldn’t focus on “best overall.” It’s about workflow matching. Here’s the decision tree we use with clients:
Future-Proof Through Model-Agnostic Architecture
2026 lesson from our MeteorAI work (built with Caylent, AWS Premier Tier Partner): Never hard-code a single model into your infrastructure.
Model releases, pricing changes, and capability shifts happen too fast. What’s optimal today may be obsolete in six months.
The solution: Routing layers
Build model-agnostic orchestration that:
- Classifies the task (simple query, complex reasoning, document extraction)
- Routes to the optimal model based on cost, latency, and accuracy requirements
- Allows model swapping in 48 hours when market conditions change
MeteorAI architecture highlights:
- Modular backend decouples business logic from model selection
- RAG integration grounds answers in company data via vector databases
- Zero Trust security (SOC2-ready for enterprise)
- Model swapping without code refactoring
This architecture reduced GenAI time-to-market by 60% and development time by 50%. More importantly, it eliminated vendor lock-in.
When OpenAI raised prices in late 2025, clients with model-agnostic architectures switched 70% of workloads to Gemini Flash within a week. Those hard-coded into GPT-5 absorbed the increase.
Implementation:
- Week 1-2: Design routing logic and classification rules
- Week 3-4: Build adapter layers for top 3-4 models
- Week 5-6: Deploy with fallback mechanisms and cost monitoring
Cost: $50K-$150K for mid-market implementations
Payback: 3-6 months via optimization savings
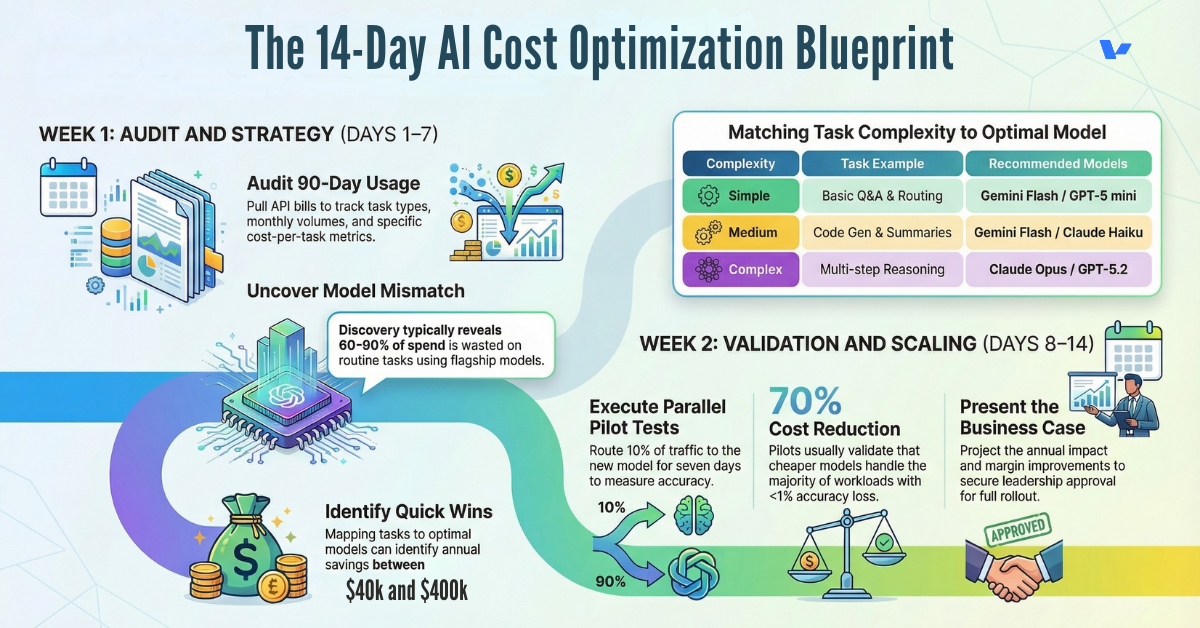
The 14-Day Fix
If you’re a CFO, CTO, or Managing Director, here’s your roadmap:
The Ugly Truth
The model landscape changes every quarter. New releases, price cuts, capability leaps, what’s optimal today won’t be optimal in six months.
What this means:
- Quarterly model reviews (reassess routing logic every 90 days)
- Cost monitoring dashboards (real-time visibility into spend per model, per task)
- A/B testing infrastructure (continuous testing of new models vs. production baseline)
- Vendor diversification (never let one provider handle >70% of volume)
Companies winning in 2026:
Are not using the “best” model. They have the discipline to match models to tasks, the infrastructure to route intelligently, and the vigilance to optimize continuously.
The Onyx story isn’t an outlier. It’s the blueprint.
Onyx achieved 50% accuracy improvement via fine-tuning, unlocked $100M+ enterprise accounts, and boosted user satisfaction by 30%, all while cutting infrastructure costs.
Your competitive advantage in 2027 won’t come from having access to GPT-5 or Claude Opus. Everyone has access. It’ll come from knowing when to use them, when to use cheaper alternatives, and when to build something custom.
The selection crisis is real. The fix is tactical. The ROI is bankable.
Guy Pistone
CEO, Valere | AWS Premier Tier Partner
Building meaningful things.
Resources & Further Reading
Model Performance & Benchmarks
- ChatGPT 5.2 vs Gemini 3 vs Claude Opus 4.5: Everything You Need to Know
- GPT-5.2 vs Llama 4 Scout – LLM Stats
- GPT-5.2 Benchmarks (Explained) – Vellum AI
- Google Gemini 3 Benchmarks (Explained) – Vellum AI
- LLM Leaderboard 2025 – Vellum AI
- SWE-Bench Pro (Public Dataset) – Scale AI
Pricing & Economic Analysis
- API Pricing – OpenAI
- Gemini Developer API Pricing
- Models Overview – Claude API Docs
- How Much Does the Gemini 3 Flash Cost? Full Pricing Breakdown
- NVIDIA H100 Price Guide 2026: GPU Costs, Cloud Pricing & Buy vs Rent
- Cost-Performance Tradeoffs: When to Use GPT-5 vs Self-Hosted Llama 4
Model-Specific Deep Dives
- Gemini 3 Flash: Frontier Intelligence Built for Speed – Google Blog
- A New Era of Intelligence with Gemini 3 – Google Blog
- Claude Opus 4.5, and Why Evaluating New LLMs Is Increasingly Difficult
- Introducing Claude Haiku 4.5 – Anthropic
- Meta Releases Llama 4 Models, Claims Edge Over AI Competitors – DeepLearning.AI
- GPT-5.2 Model | OpenAI API
Technical Implementation Guides
- Running Llama 4 Scout on a Single NVIDIA H100 using INT4 Quantization
- How to Deploy LLaMA 4 Models in Your VPC or Cloud – Predibase
- NVIDIA Accelerates Inference on Meta Llama 4 Scout and Maverick
- Claude Haiku 4.5 Deep Dive: Cost, Capabilities, and the Multi-Agent Opportunity | Caylent
Valere Case Studies
- Onyx AI: Enterprise AWS Cloud Migration & AI-Native Chatbot Development
- Valere: Turning Data into Business Innovation
- Valere Reviews 2026: Details, Pricing, & Features | G2
Industry Analysis & Market Trends
- LLM Roundup: A Wave of New Releases Winds Down the Year – AIwire
- Stanford AI Experts Predict What Will Happen in 2026
- Gemini 3 Launch: Benchmark, Pricing & How to Access – GrowthJockey
- Gemini 3 Flash vs GPT-5.2 vs Claude Opus 4.5 vs Grok 4.1, The Real Winner Surprised Me


